
Command Lines
AI Coding's Control Spectrum

In the early 1950s, Grace Hopper coined the term “compiler” and built one of the first versions with her A-0 system1. The compilers that followed abstracted away machine code, letting programmers focus on higher-level logic instead of lower-level hardware details. Today, AI coding assistants2 are enabling a similar change, letting software engineers focus on higher-order work by generating code from natural language prompts3. Everyone from big tech to well-funded startups is competing to capture this shift. Yesterday Google announced Antigravity, their new AI coding assistant, and the day before, AWS announced the general availability of their AI coding tool, Kiro. Last week, Cursor, the standout startup in this space, raised $2.3B in their series-D round at a valuation of $29.3B.
Two lines in Cursor’s press release stood out to me. The first:
We’ve also crossed $1B in annualized revenue, counting millions of developers.
This disclosure means Anysphere Inc. (Cursor’s parent company) is the fastest company in history to reach $1B in annual recurring revenue (ARR). Yes, faster than OpenAI, and faster than Anthropic4.
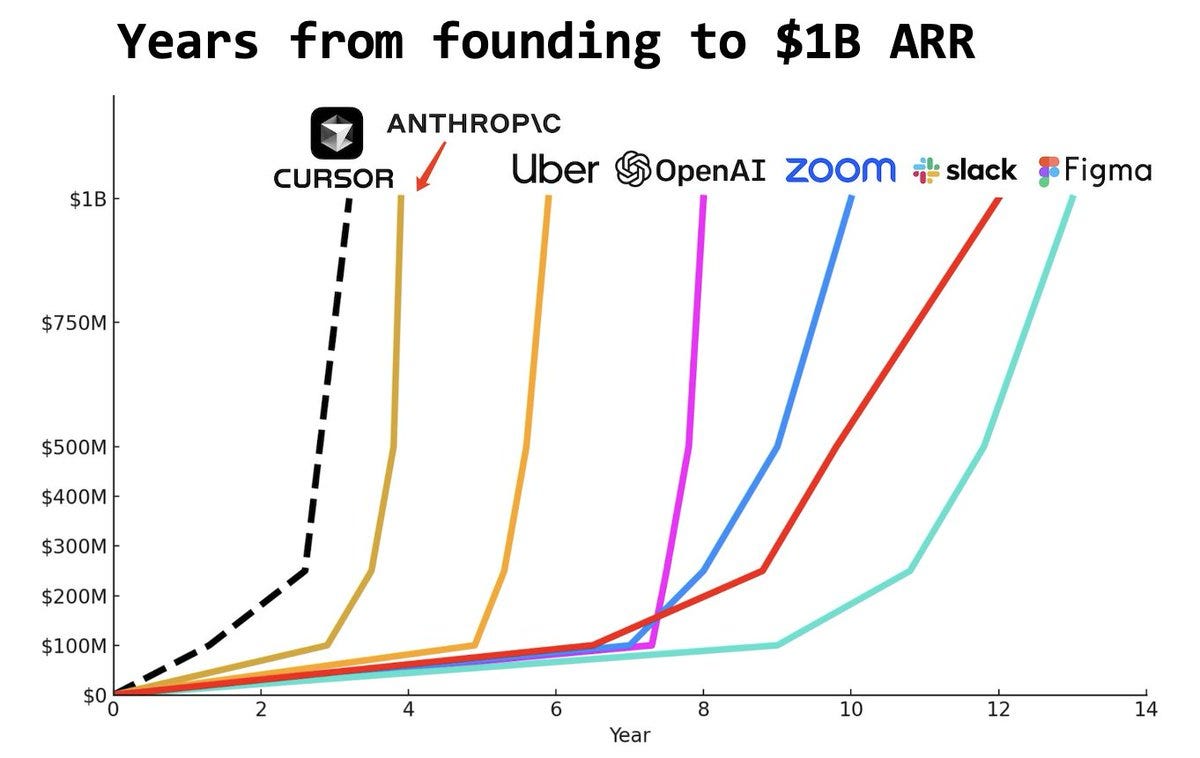
Engineers are trying every new AI coding tool. As a result, the AI-coding tool market is growing exponentially (+5x in just over a year)5. But it’s still early. As I wrote in Why Some AI Wrappers Build Billion-dollar Businesses, companies spend several hundred billion dollars a year on software engineering, and AI has the potential to unlock productivity gains across that entire spend.
Software developers represent roughly 30% of the workforce at the world’s five largest market cap companies, all of which are technology firms as of October 2025. Development tools that boost productivity by even modest percentages unlock billions in value.
In my view, this nascent market is splitting based on three types of users.
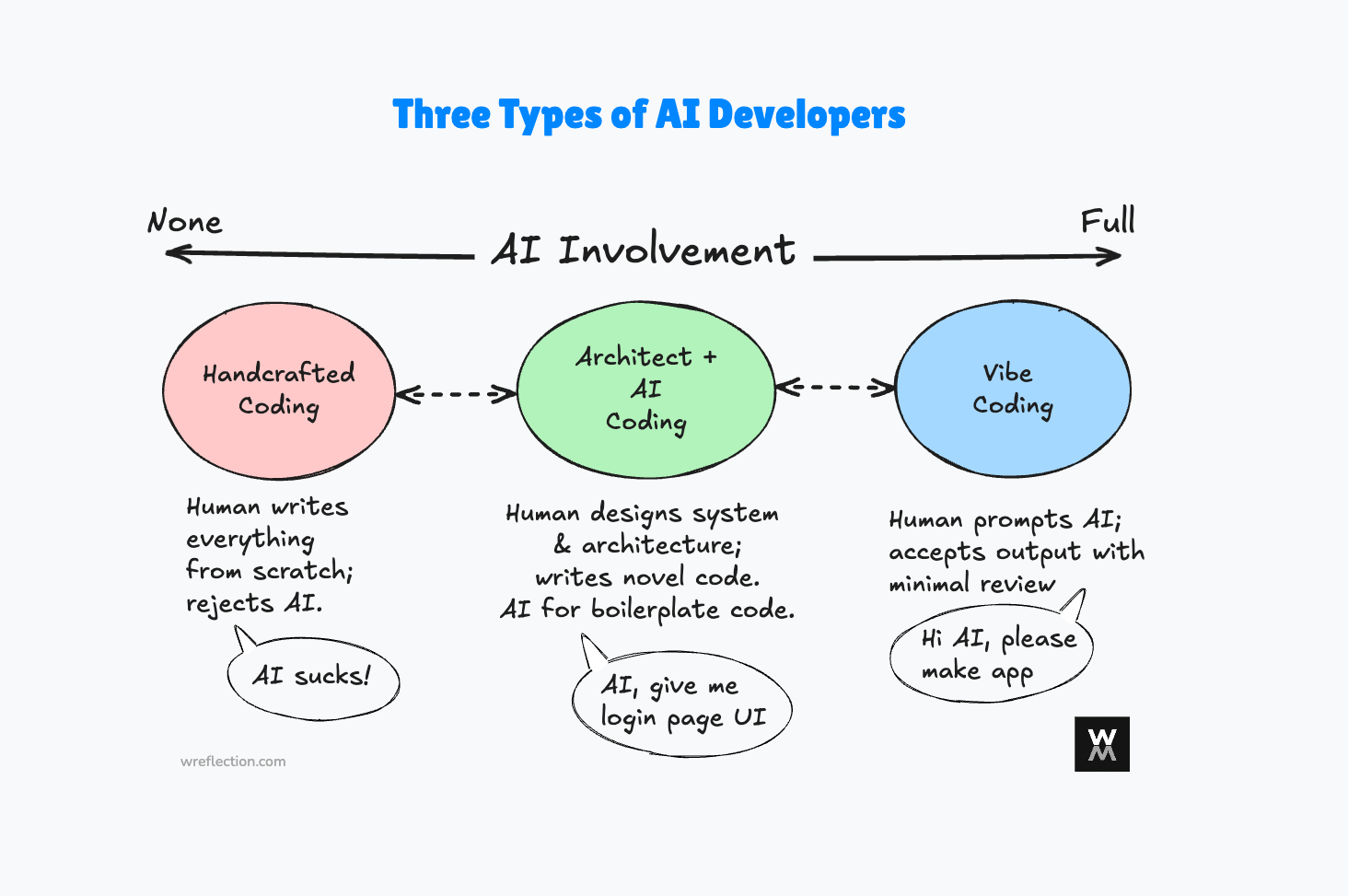
On one end is Handcrafted Coding. These are engineers who actively decline to use LLMs, either because of skepticism about quality or insistence on full control of every code. They argue that accepting AI suggestions creates technical debt you cannot see until it breaks in production. This segment continues to decline as the quality of AI coding models improves.
The opposite end is Vibe Coding. These are typically non-engineers, who use AI to build concepts and prototypes. They prompt the model hoping for an end-to-end solution, accept the output with minimal review, and trust that it works. The user describes what they want and lets the model figure out the implementation details of how to build it.
In the middle sits Architect + AI Coding. The engineer uses the AI/LLM as a pair programmer exploring system designs, analyzing data models, and reviewing API details. When the work is something entirely new or something that needs careful handling, the human programmer still codes those pieces by hand. But for boilerplate code, package installations, generic User Interface (UI) components, and any kind of code that is typically found on the internet, they assign it to the model6. The engineer stays in command of what is important to them and delegates what is not.
The Market Split
Based on the user types, I think, the AI coding market splits into two.
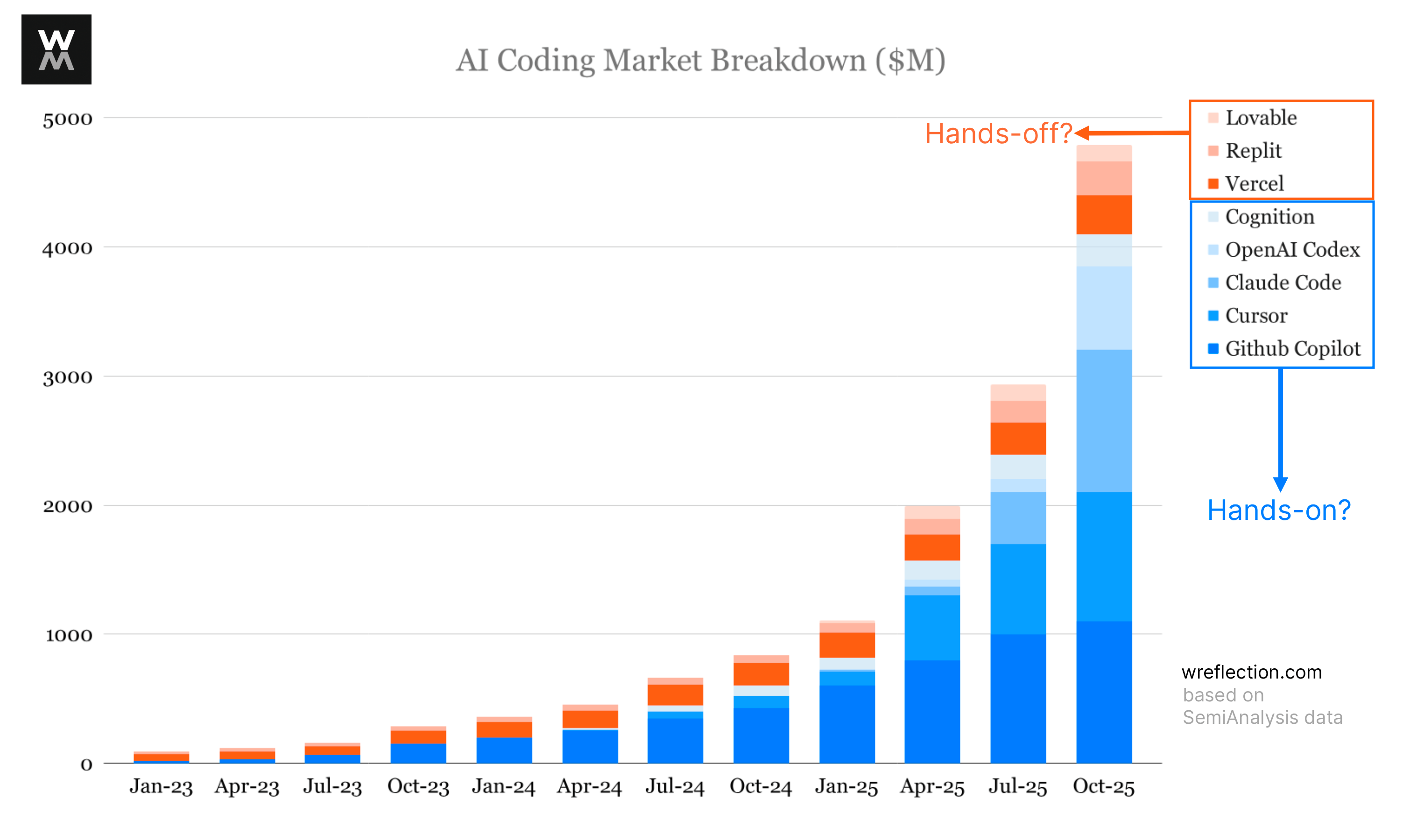
Hands-off: Non-engineers (product managers, designers, marketers, other internal employees) use these tools to vibe code early product concepts. They look to AI as the lead engineer to spin-up concepts/prototypes of apps, websites, and tools by simply prompting the AI to make something for them. Lovable, Vercel, Bolt, Figma Make, and Replit fit here7. Code from these users, as of now, are not typically pushed to prod.
Hands-on: Professional software engineers use these tools in their existing workflow to ship production code. They use AI as an assistant to write boilerplate code, refactor existing services, wire new features or UI screens, and triage bugs in codebases. Cursor, Claude Code, OpenAI Codex, Github Copilot, Cline, AWS Kiro play here. These products live where the work is done, and integrate into the engineer’s workflow. This is, at least as of now, the bigger market segment.
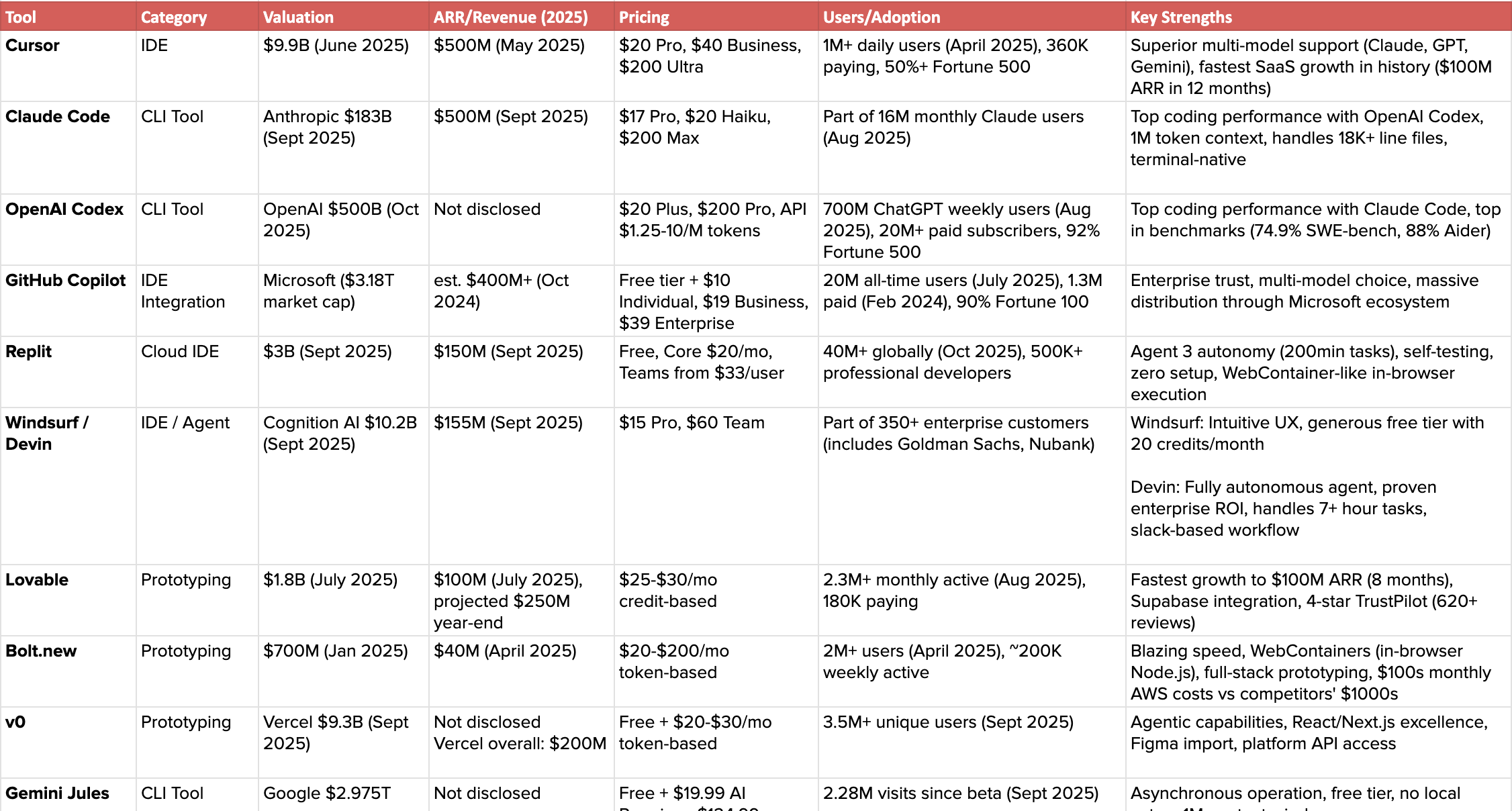
To see an evaluation of all the major AI coding tools currently in the market, checkout this breakdown by Peter Yang, who runs the newsletter Behind The Craft.
{kind=link}
That brings me to the second thing in Cursor’s press release that stood out to me:
Our in-house models now generate more code than almost any other LLMs in the world.
While I am not convinced about that claim8, what I am convinced about is that Cursor is still growing despite its previous reliance on foundation models. From Why Some AI Wrappers Build Billion-dollar Businesses again:
But Cursor and other such tools depend almost entirely on accessing Anthropic, OpenAI and Gemini models, until
open-sourceopen-weight and in-house models match or exceed frontier models in quality. Developer forums are filled with complaints about rate limits from paying subscribers. In my own projects, I exhausted my Claude credits in Cursor mid-project and despite preferring Cursor’s user interface and design, I migrated to Claude Code (and pay ten times more to avoid rate limits). The interface may be better, but model access proved decisive.
Cursor’s new in-house model Composer-2, which just launched last month, is a good example of how this model versus application competition is evolving. Cursor claims (without any external benchmarks, I must say) that Composer-2 is almost as good as frontier models but 4x faster. It’s still early to say how true that is. Open-source models have not yet come close to the top spots in SWE-bench verified or in private evals9.

To me, model quality is the most decisive factor in these AI coding wars. And in my view, that’s why Claude Code has already overtaken Cursor, and OpenAI’s Codex is close behind, despite both having launched a year or so later.
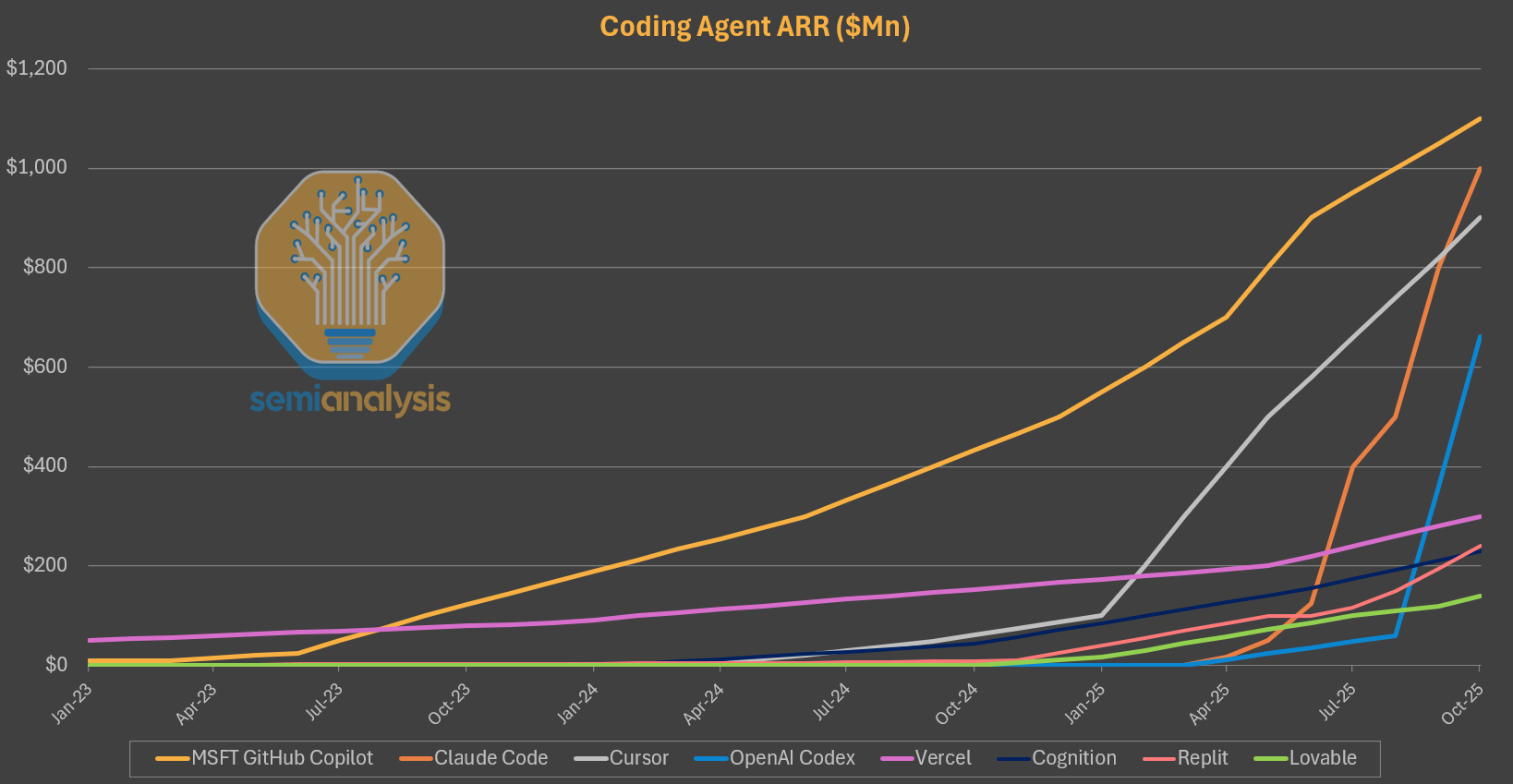
Even though the newcomers Cursor, Claude Code, and OpenAI Codex are the talk of the (developer) town, incumbents such as Microsoft with Github Copilot, AWS with Kiro, and Google with Antigravity, can utilize their existing customer relationships, bundle their offerings with their existing suites, and/or provide their option as the default in their tech stack to compete. As an example, Cursor charges $20–$40 monthly per user for productive usage, while Google Antigravity launched free with generous limits for individual users. Github Copilot still leads this market, proving once again that enterprise bundling and distribution has structural advantages. This is the classic Microsoft Teams vs. Slack Dynamic10.
One way for startups to compete is by winning individual users who may use a coding tool with or without formal approval, and then be the tool’s evangelist inside the organization. That organic interest and adoption eventually forces IT and security teams to officially review the tool and then eventually sanction its usage.
Yet, even as these newer tools capture developer mindshare, the underlying developer tools market is changing. Both the IDEs developers choose and the resources they we consult have changed dramatically. StackOverflow, once the default for programmers stuck on a programming issue, has seen its traffic and number of questions decline dramatically since ChatGPT’s launch, suggesting that AI is already replacing some traditional developer resources.
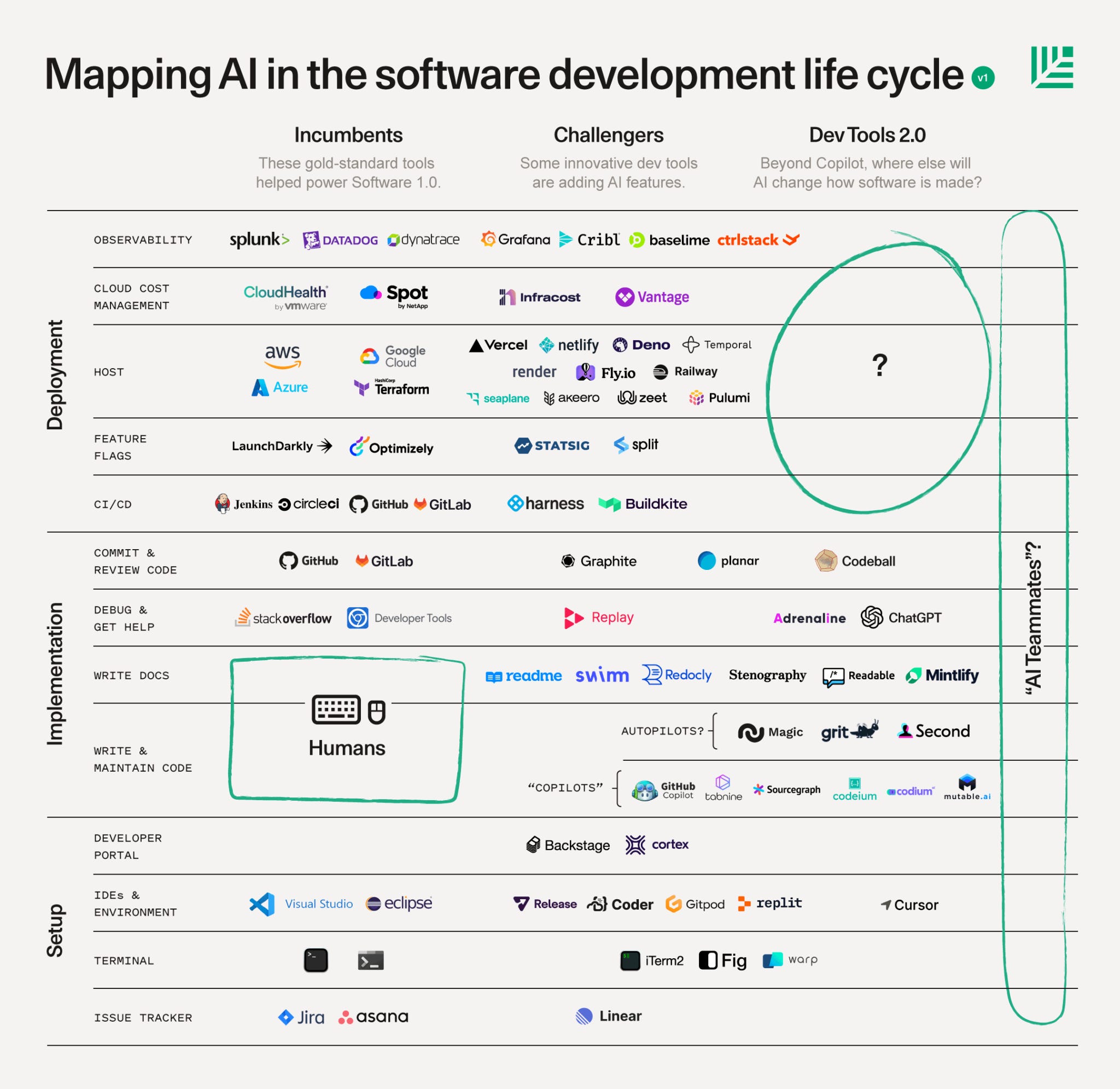
Just as compilers freed programmers from writing assembly code, AI tools are freeing software engineers from the grunt work of writing boilerplate and routine code, and letting them us focus on higher-order thinking. Eventually, one day, AI may get so good that it will generate applications on demand and create entire software ecosystems autonomously. Both hands-off and hands-on AI coding tools, as well as incumbents and newcomers, see themselves as the path to that fully autonomous software generation, even if they are taking different approaches. The ones who get there will be those who deliver the best model quality that ships code reliably, go deep enough to ship features that foundation models can’t care enough to replicate, and become sticky enough that users will not leave even when they can11.
If you enjoyed this post, please consider liking it on Twitter/X or LinkedIn, or sharing it with someone who might also find it interesting
Hopper’s A-0 system and her definition of the term compiler is different from what we consider a compiler today, but it established the foundational concept.
In the context of coding assistants, most products labeled as AI tools are powered by LLMs, and so I use AI and LLM interchangeably in this article despite the actual difference.
A better comparison might be at the product level rather than company level. In that case, ChatGPT and Claude both reached $1B faster than Cursor did.
I would argue that the vast majority of productive code is hidden behind company firewalls. Current foundation models are trained on publicly available data on the internet, and do not have access to proprietary codebases. We are yet to see breakthrough solutions where a company augments their confidential private data to generate production-ready code using current LLMs. While Retrieval-Augmented Generation has shown some promise, it has not yet delivered transformative results. Companies such as Glean are actively working on this problem.
Replit and Cognition probably appeal to both segments. To me, Replit leans hands-off with its rapid prototyping focus. Cognition’s agent-based approach, though hands-off, lets engineers still control the code directly, making it lean hands-on.
I was curious how Cursor knows how much code is generated by other LLMs outside Cursor? When I asked this on hackernews, swyx suggested that they “can pretty much triangulate across openrouter x feedback from the top 3 model labs to compare with internal usage and figure that out”. To me, triangulation makes sense for internal estimates. but for external publication, I’m surprised Cursor didn’t include “we estimate” or similar qualifying language. My understanding is that FTC policy requires substantiation before making definitive comparative claims (like more than, better than etc). All that to say, I’m not fully convinced about their claims.
SWE-bench is a benchmark for evaluating large language models (LLMs) on real world software engineering tasks and issues collected from GitHub. Performance against public benchmarks can be gamed by the model builders. Currently after any new model launch, we see people using the model in the wild and forming a consensus around how the model performs which is a better indicator than these benchmarks.
Microsoft bundled Teams into Office 365 subscriptions at no extra cost, using its dominant enterprise distribution to surpass Slack’s paid standalone product within three years despite Slack’s earlier launch and product innovation. See https://venturebeat.com/ai/microsoft-teams-has-13-million-daily-active-users-beating-slack
Natasha Malpani, Twitter/X, 2025
“One way for startups to compete is by winning individual users who may use a coding tool without formal approval, and then be the tool’s advocate inside the organization.” Working at a smaller company I can definitely say this is true! We actually had our tech leadership ask devs to suggest different AI tools and then got trials / limited seats on those to go through a pilot phase.